GenAI-OCR: Direkte Transformation von Dokumenten zu strukturierten Daten
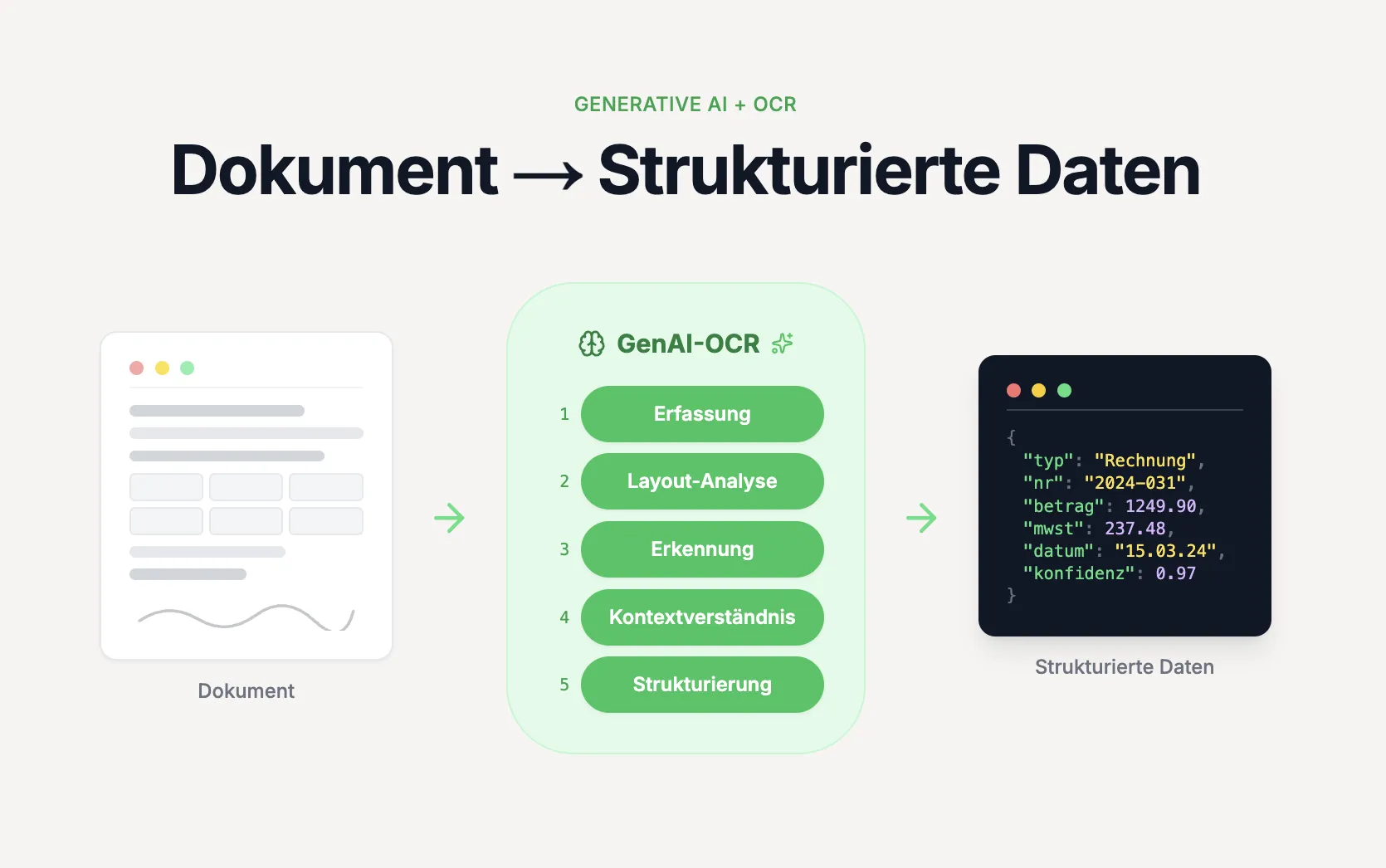
Klassische OCR extrahiert Text aus Dokumenten – aber nur als Rohdaten: Zeilen, Wörter, Koordinaten, Bounding-Boxes. Was fehlt, ist das Verständnis. Wer strukturierte Daten braucht, muss nach der OCR selbst parsen, Regeln definieren und Vorlagen pflegen. GenAI-OCR eliminiert diesen Zwischenschritt komplett.
Was ist GenAI-OCR?
GenAI-OCR ist die direkte Transformation von unstrukturierten Dokumenten in strukturierte Daten. Statt erst Zeichen zu erkennen, Positionen zu berechnen und Rohtext auszugeben, versteht ein generatives KI-Modell das Dokument semantisch und liefert sofort das gewünschte Ausgabeformat – ob JSON, CSV oder ein individuelles Schema.
Das Modell sieht das Dokument so, wie ein Mensch es lesen würde: Es erkennt, dass eine Zahl neben dem Wort Betrag eine Rechnungssumme ist, nicht bloß eine Zeichenkette an Position (x:412, y:308).
Klassische OCR: Der Umweg über Koordinaten
Traditionelle OCR-Systeme arbeiten positionsbasiert:
- Das Bild wird in Pixel-Regionen zerlegt
- Zeichen werden einzeln erkannt und mit Koordinaten versehen
- Ergebnis: Rohtext mit Bounding-Boxes (x, y, Breite, Höhe)
- Die Bedeutung der Daten bleibt unbekannt
- Nachgelagerte Systeme müssen Regeln und Templates definieren, um daraus Struktur zu gewinnen
Dieser Prozess ist aufwändig, fragil und bricht bei jedem neuen Dokumentlayout.
GenAI-OCR: Direkt zur Struktur
GenAI-OCR überspringt den gesamten Zwischenschritt. Ein multimodales Sprachmodell nimmt das Dokument als Input und gibt direkt die gewünschte Datenstruktur aus:
- Kein Zwischenschritt über Koordinaten oder Rohtext
- Das Modell versteht Kontext: Es weiß, dass 1.249,90 neben MwSt ein Steuerbetrag ist
- Beliebige Ausgabeformate: JSON, XML, Tabellen, individuelle Schemata
- Funktioniert ohne Templates – jedes Dokumentlayout wird verstanden
- Mehrsprachig und handschrifttauglich ohne Zusatzkonfiguration
Der Unterschied auf einen Blick
| Klassische OCR | GenAI-OCR | |
|---|---|---|
| Ausgabe | Rohtext + Koordinaten | Strukturierte Daten (JSON, XML) |
| Verständnis | Keines – nur Zeichenerkennung | Semantisch – versteht Bedeutung |
| Templates | Zwingend erforderlich | Nicht nötig |
| Neues Layout | Bricht / muss neu konfiguriert werden | Funktioniert sofort |
| Nachverarbeitung | Umfangreiche Regeln und Parsing | Keine – Daten sind direkt nutzbar |
| Handschrift | Stark fehleranfällig | Kontextbasiert korrigiert |
Warum das wichtig ist
Der klassische OCR-Workflow erzeugt technische Schulden: Für jedes Dokumentformat braucht man Templates, Regex-Regeln und Koordinaten-Mappings. Bei Layout-Änderungen bricht alles. GenAI-OCR eliminiert diese Abhängigkeiten:
- Keine Template-Pflege mehr
- Keine positionsbasierten Extraktionsregeln
- Keine fragilen Regex-Parser für Rechnungsnummern oder Beträge
- Neue Dokumenttypen funktionieren ohne Anpassung
- Das Modell lernt kontextuell, nicht koordinatenbasiert
Einsatzszenarien
- Rechnungen: Direkte Extraktion aller Positionen, Beträge und Metadaten als JSON – egal welches Layout
- Verträge: Klauseln, Fristen und Konditionen werden semantisch erkannt und strukturiert ausgegeben
- Formulare: Handschriftliche Eingaben werden kontextuell verstanden, nicht nur zeichenweise gelesen
- Belege: Kassenbons, Quittungen und Tickets werden unabhängig vom Format direkt in Buchungsdaten transformiert
- Ausweise: KYC-Daten werden strukturiert extrahiert, ohne vorher Koordinaten-Templates zu definieren
Fazit
GenAI-OCR ist kein besseres OCR – es ist ein fundamental anderer Ansatz. Statt den Umweg über Koordinaten, Rohtext und nachgelagertes Parsing zu nehmen, transformiert es Dokumente direkt in die Datenstruktur, die Ihr System braucht. Das Modell versteht, was es sieht.
Mit Plurali nutzen Sie GenAI-OCR als Kern unserer IDP-Plattform: Dokument rein, strukturierte Daten raus – ohne Templates, ohne Regeln, ohne Zwischenschritte.